
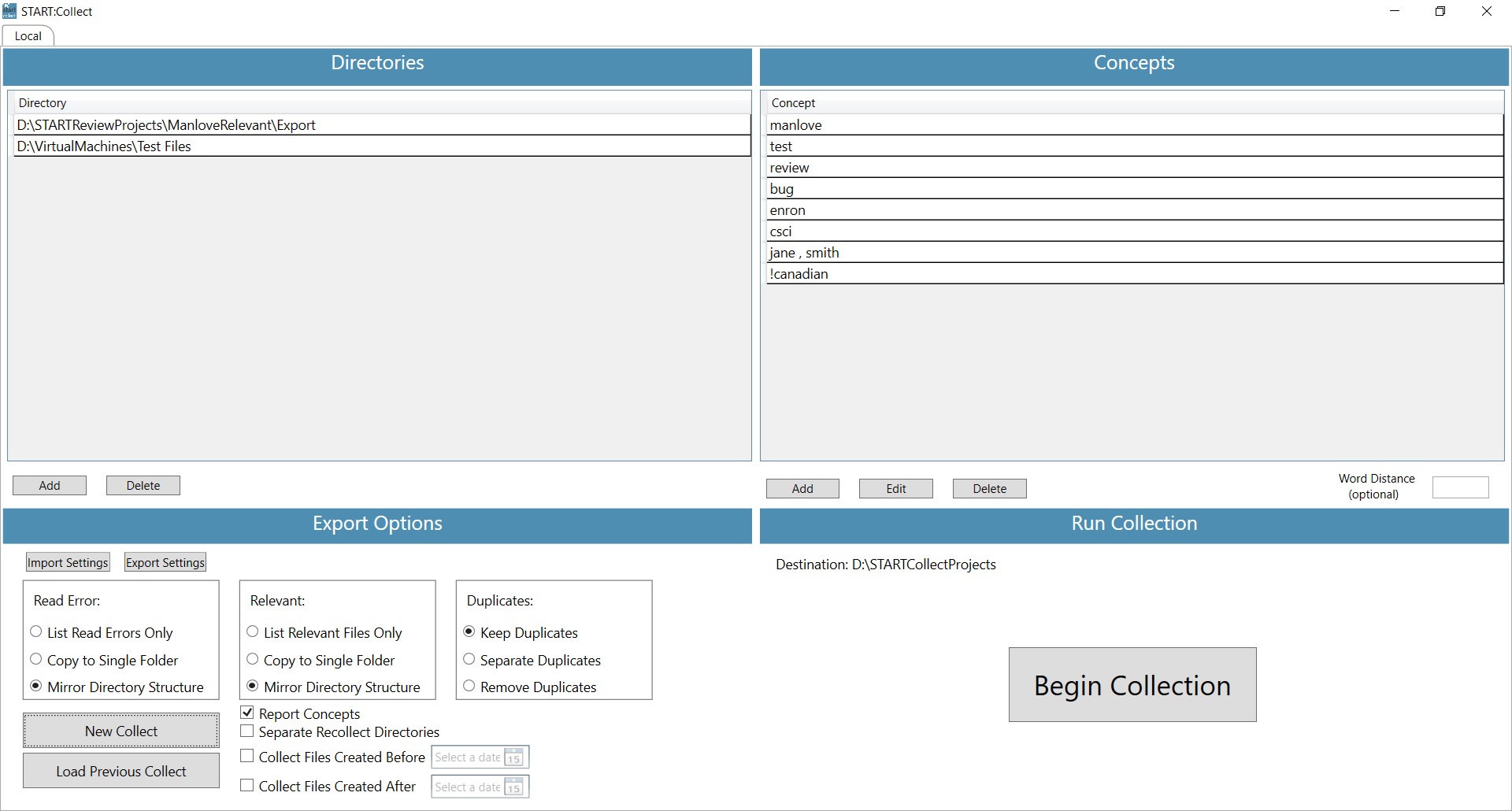
Start:Collect is an application for Windows built with SQLite, C#, and WPF. It searches through one or more directories for documents that contain user-specified keywords and exports the narrowed dataset for the user to manually review or to import and review within Agile Data Solutions’ complementary product Start:Review. Following are some of the more detailed features Start:Collect offers:
- Support documents (.docx, .doc, .rtf, .odt), PDFs, text files, PowerPoints, Spreadsheets, images (.tif, .tiff, .jpeg, .jpg, .png), HTML files, email collections (.pst, .ost, .mbox), and email files (.msg, .eml, .emlx).
- Perform OCR to read text from images and PDFs.
- Include files that contain one or more keywords in the export set.
- Exclude files that contain one or more keywords from the export set.
- Consider files relevant or non-relevant only if all the keywords in a group appear within a certain word distance.
- Include only files that were created within a user-specified timeframe.
- Export files Start:Collect can’t read for manual review.
- Allow users to specify how to copy relevant and unreadable files into the export directory: copy files directly into the export directory, copy files in a directory structure that mirrors the import structure, or list the files in an output text file.
- Remove or separate duplicates from the results.
- Save collection settings to a file and import them to quickly populate the Start:Collect interface with word groups, directories, and selected options.
- Open an existing Start:Collect project to recollect files from its existing input directories every time the data or keywords change without producing duplicates in the output.
Start:Collect has gone through two redesigns since a student at the University of Montana initially created a prototype for Agile. I oversaw a team of two developers who redesigned the original, converting it from a console application to a WPF application that could handle much larger datasets. Unfortunately, with my focus primarily on Start:Review, I didn’t watch them close enough. To stabilize the product and allow it to handle even larger datasets, I performed extensive debugging and a partial redesign later. Before Agile’s closure, I’d created a plan to completely redesign Start:Collect for true stability, flexibility, and maintainability, basing the new design on the multi-threaded import, export, and marking processes I’d built in Start:Review. I also programmed several of Start:Collect’s features such as the ability to save and import settings, detect and handle duplicates in the results, and search through files within a time frame.